// The contents of this file are in the public domain. See LICENSE_FOR_EXAMPLE_PROGRAMS.txt
/*
This is an example illustrating the use of the linear model predictive
control tool from the dlib C++ Library. To explain what it does, suppose
you have some process you want to control and the process dynamics are
That is, the next state the system goes into is a linear function of its
described by the linear equation:
x_{i+1} = A*x_i + B*u_i + C
current state (x_i) and the current control (u_i) plus some constant bias or
disturbance.
drive the state (x) to some reference value, which is what we show in this
A model predictive controller can find the control (u) you should apply to
example. In particular, we will simulate a simple vehicle moving around in
*/
a planet's gravity. We will use MPC to get the vehicle to fly to and then
hover at a certain point in the air.
#include <dlib/gui_widgets.h>
#include <dlib/control.h>
#include <dlib/image_transforms.h>
using namespace std;
using namespace dlib;
// ----------------------------------------------------------------------------
{
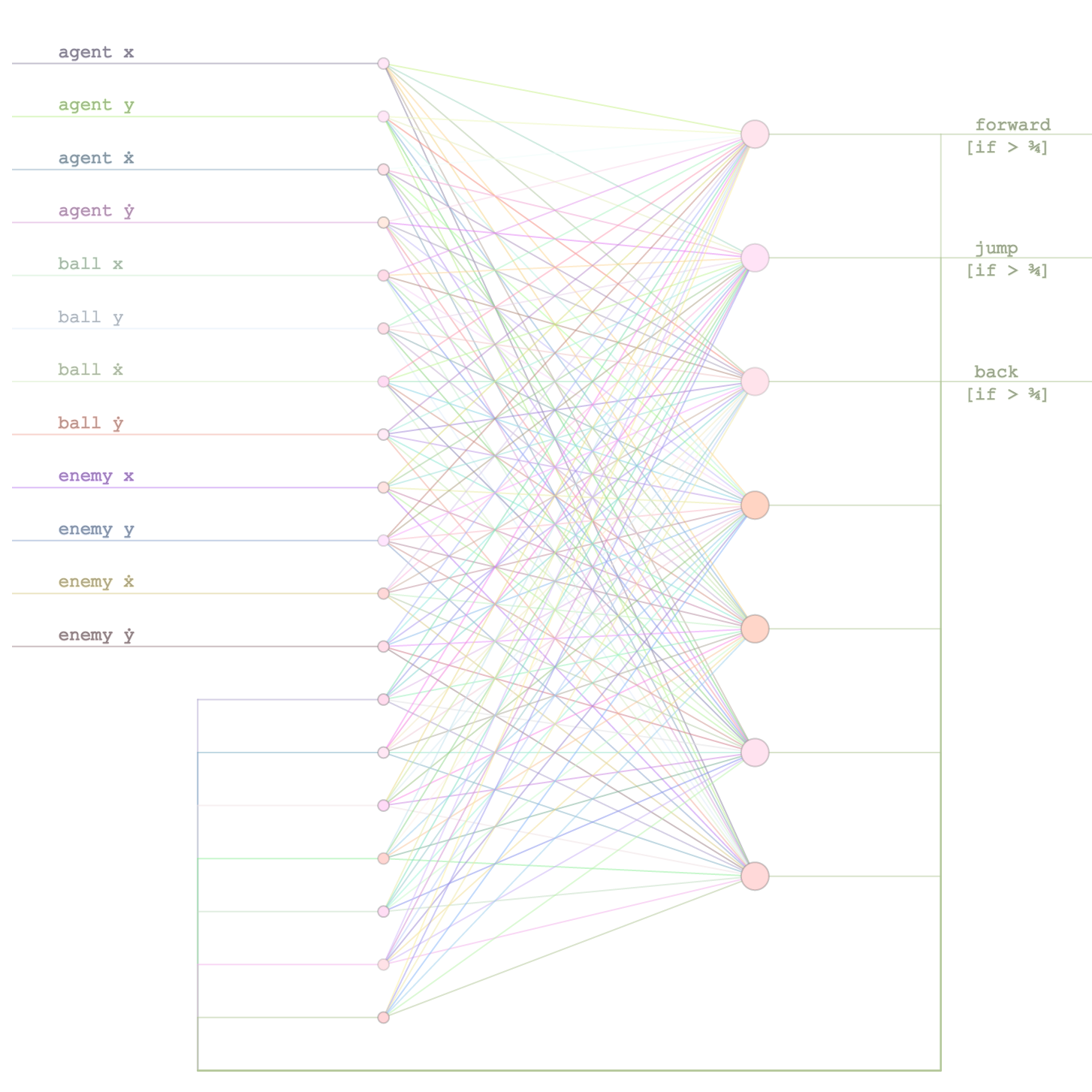
const int STATES = 4;
const int CONTROLS = 2;
// The first thing we do is setup our vehicle dynamics model (A*x + B*u + C).
// Our state space (the x) will have 4 dimensions, the 2D vehicle position
// and also the 2D velocity. The control space (u) will be just 2 variables
// which encode the amount of force we apply to the vehicle along each axis.
// Therefore, the A matrix defines a simple constant velocity model.
matrix<double,STATES,STATES> A;
A = 1, 0, 1, 0, // next_pos = pos + velocity
0, 1, 0, 1, // next_pos = pos + velocity
0, 0, 1, 0, // next_velocity = velocity
0, 0, 0, 1; // next_velocity = velocity
// Here we say that the control variables effect only the velocity. That is,
// the control applies an acceleration to the vehicle.
matrix<double,STATES,CONTROLS> B;
B = 0, 0,
0, 0,
1, 0,
0, 1;
// Let's also say there is a small constant acceleration in one direction.
// This is the force of gravity in our model.
matrix<double,STATES,1> C;
C = 0,
0,
0,
0.1;
const int HORIZON = 30;
// Now we need to setup some MPC specific parameters. To understand them,
// let's first talk about how MPC works. When the MPC tool finds the "best"
// control to apply it does it by simulating the process for HORIZON time
// steps and selecting the control that leads to the best performance over
// the next HORIZON steps.
//
// To be precise, each time you ask it for a control, it solves the
// following quadratic program:
//
// min sum_i trans(x_i-target_i)*Q*(x_i-target_i) + trans(u_i)*R*u_i
// x_i,u_i
//
// such that: x_0 == current_state
// x_{i+1} == A*x_i + B*u_i + C
// lower <= u_i <= upper
// 0 <= i < HORIZON
//
// and reports u_0 as the control you should take given that you are currently
// in current_state. Q and R are user supplied matrices that define how we
// penalize variations away from the target state as well as how much we want
// to avoid generating large control signals. We also allow you to specify
// upper and lower bound constraints on the controls. The next few lines
// define these parameters for our simple example.
matrix<double,STATES,1> Q;
// Setup Q so that the MPC only cares about matching the target position and
// ignores the velocity.
Q = 1, 1, 0, 0;
matrix<double,CONTROLS,1> R, lower, upper;
R = 1, 1;
lower = -0.5, -0.5;
upper = 0.5, 0.5;
// Finally, create the MPC controller.
mpc<STATES,CONTROLS,HORIZON> controller(A,B,C,Q,R,lower,upper);
// Let's tell the controller to send our vehicle to a random location. It
// will try to find the controls that makes the vehicle just hover at this
// target position.
dlib::rand rnd;
matrix<double,STATES,1> target;
target = rnd.get_random_double()*400,rnd.get_random_double()*400,0,0;
controller.set_target(target);
// Now let's start simulating our vehicle. Our vehicle moves around inside
// a 400x400 unit sized world.
matrix<rgb_pixel> world(400,400);
image_window win;
matrix<double,STATES,1> current_state;
// And we start it at the center of the world with zero velocity.
current_state = 200,200,0,0;
int iter = 0;
while(!win.is_closed())
{
// Find the best control action given our current state.
matrix<double,CONTROLS,1> action = controller(current_state);
cout << "best control: " << trans(action);
// Now draw our vehicle on the world. We will draw the vehicle as a
// black circle and its target position as a green circle.
assign_all_pixels(world, rgb_pixel(255,255,255));
const dpoint pos = point(current_state(0),current_state(1));
const dpoint goal = point(target(0),target(1));
draw_solid_circle(world, goal, 9, rgb_pixel(100,255,100));
draw_solid_circle(world, pos, 7, 0);
// We will also draw the control as a line showing which direction the
// vehicle's thruster is firing.
draw_line(world, pos, pos-50*action, rgb_pixel(255,0,0));
win.set_image(world);
// Take a step in the simulation
current_state = A*current_state + B*action + C;
dlib::sleep(100);
// Every 100 iterations change the target to some other random location.
++iter;
if (iter > 100)
{
iter = 0;
target = rnd.get_random_double()*400,rnd.get_random_double()*400,0,0;
controller.set_target(target);
}
}
}
// ----------------------------------------------------------------------------